The Gutenberg Editor doesn’t support copying all the content in plain text as it was the case with the Classic editor. Instead, the HTML markup is included whenever multiple blocks are pasted in a plain text editor like Notepad.
The only exception to this rule is when copying individual blocks. In that case, the HTML tags are not included. It’s however not practical to copy multiple blocks individually.
According to a GitHub issue related to this behaviour, the logic behind this is to allow copying content between posts without losing the block information.
This makes perfect sense for those that primarily use the block editor for authoring their posts, however it’s quite counterintuitive to those that edit their posts with the help of external editors that don’t render the HTML.
Ideally, it would be preferable if users could set a default copying behaviour between the HTML or the plain text copier. This way, all users get access to the best of both worlds and can switch seamlessly whenever the need for either arises.
While we wait for some kind of compromise in that direction, here are some few workarounds that you can use to copy the blocks in plain text only.
Update 01/2024: It is now possible to copy and paste multiple blocks without the HTML comment tag. Issue closed.
1. Use a Temporary Classic Block
The classic block works just like the classic editor. What this means is that you can make use of the block temporarily to make a plain text copy while still using the Gutenberg Editor. To do this:
- Create a classic block at the bottom of the post.
- Copy all the paragraphs or the blocks you need copying.
- Paste the content in the classic block.
- Copy the content in the classic block to your plain text editor.
- Delete the classic block.
2. Use a Word Processor
Unlike plain or rich text editors, Word Processors like Microsoft Word and Google Docs, support rendering HTML.
As such, when you paste content into them from Gutenberg, all the copied content, not just the text, will be formatted as it was in the editor. However, copying content from the Word Processor to a plain text editor will not carry over its underlying markup.
We can therefore use this as a way to convert the HTML copy into plain text as follows:
- Copy the content from the Gutenberg Editor.
- Paste it into Word, LibreOffice Writer or Google Docs.
- Copy the content from the Word Processor to your Plain Text Editor.
I’ve only tested those three processors, however I expect others to work just the same.
3. Use Find and Replace Regular Expression
If you use a text editor that supports RegEx such as Notepad++ or Sublime Text, you can quickly strip way all the Gutenberg HTML tags using an expression as follows:
- Copy and paste the blocks into the text editor.
- Put the cursor at the very beginning.
- Open the Find and Replace window or panel.
- Enable searching Regular Expressions.
- Enter the RegEx
<[^>]+>in the Find what box and leave the Replace with box empty.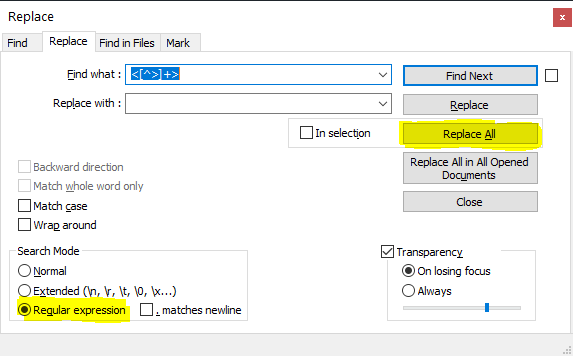
- Replace all the matches.
The HTML tags and everything inside them will be removed leaving the text content only.
Strip Away HTML using an Online Service
There are plenty of online tools such as wtools and StripHTML that can help you remove tags from any HTML code.
Just copy the blocks and paste the code into one of the tools and strip the tags. You can then copy the bare text to your plain text editor.
